Kafka-introduction
2020 It邦幫忙鐵人賽 系列文章
- ELK Stack
- Self-host ELK stack on GCP
- Secure ELK Stask
- 監測 Google Compute Engine 上服務的各項數據
- 監測 Google Kubernetes Engine 的各項數據
- 是否選擇 ELK 作為解決方案
- 使用 logstash pipeline 做數據前處理
- Elasticsearch 日常維護:數據清理,效能調校,永久儲存
- Debug ELK stack on GCP
- Kafka HA on Kubernetes(6)
- Deploy kafka-ha
- Kafka Introduction
- kafka 基本使用
- kafka operation scripts
- 集群內部的 HA topology
- 集群內部的 HA 細節
- Prometheus Metrics Exporter 很重要
- 效能調校
於我比較熟悉 GCP / GKE 的服務,這篇的操作過程都會以 GCP 平台作為範例,不過操作過程大體上是跨平台通用的。
寫文章真的是體力活,覺得我的文章還有參考價值,請左邊幫我點讚按個喜歡,右上角幫我按個追縱,底下歡迎留言討論。給我一點繼續走下去的動力。
對我的文章有興趣,歡迎到我的網站上 https://chechia.net 閱讀其他技術文章,有任何謬誤也請各方大德直接聯繫我,感激不盡。

寫了部屬,本想談一下 kafka 的高可用性配置,看到大德的留言,才想到應該要先跟各位介紹一下 kafka,跟 kafka 的用途。也感謝大德路過發問,我也會順代調整內容。今天就說明何為 kafka,以及在什麼樣的狀況使用。
摘要
- 簡介 kafka
- 基本元件
- Kafka 的工作流程
簡介 Kafka
Kafka 是分散式的 streaming platform,可以 subscribe & publish 訊息,可以當作是一個功能強大的 message queue 系統,由於分散式的架構,讓 kafka 有很大程度的 fault tolerance。原版的說明在這邊
這邊有幾個東西要解釋。
Message Queue System
當一個系統開始運作時,裡頭會有很多變數,這些變數其實就是在一定的範圍(scope)內,做訊息(message)的傳遞。例如在 app 寫了一個 function ,傳入一個變數的值給 function。
在複雜的系統中,服務元件彼此也會有傳遞訊息的需求。例如我原本有一個 api-server,其中一段程式碼是效能瓶頸,我把它切出來獨立成一個 worker 的元件,讓它可以在更高效能地方執行,甚至 horizontal scaling。這種情境,辨可能歲需要把一部分的 message 從 api-server 傳到 worker,worker 把吃效能的工作做完,再把結果回傳給 api-server。這時就會需要一個穩定的 message queue system,來穩定,且高效能的傳遞這些 message。
Message Queue System 實做很多,ActiveMQ, RabbitMQ, … 等,一些 database 做 message queue 在某些應用場景下也十分適合,例如 Redis 是 in-memory key-value database,內部也實做 pubsub,能夠在某些環境穩定的傳送 message。
Request-Response vs Publish-Subscribe
訊息的傳送有很多方式,例如 Http request-response 很適合 server 在無狀態(stateless) 下接受來自客戶端的訊息,每次傳送都重新建立新的 http connection,這樣做有很多好處也很多壞處。其中明顯的壞處是網路資源的浪費,以及訊息的不夠即時,指定特定收件人時發件人會造成額外負擔等。
使用 Pub-sub pattern的好處,是 publisher 不需要額外處理『這個訊息要送給誰』的工作,而是讓 subscriber 來訂閱需要的訊息類別,一有新的 event 送到該訊息類別,直接透過 broker 推播給 subscriber。不僅即時,節省效能,而且訂閱的彈性很大。
Kafka producer & Consumer API
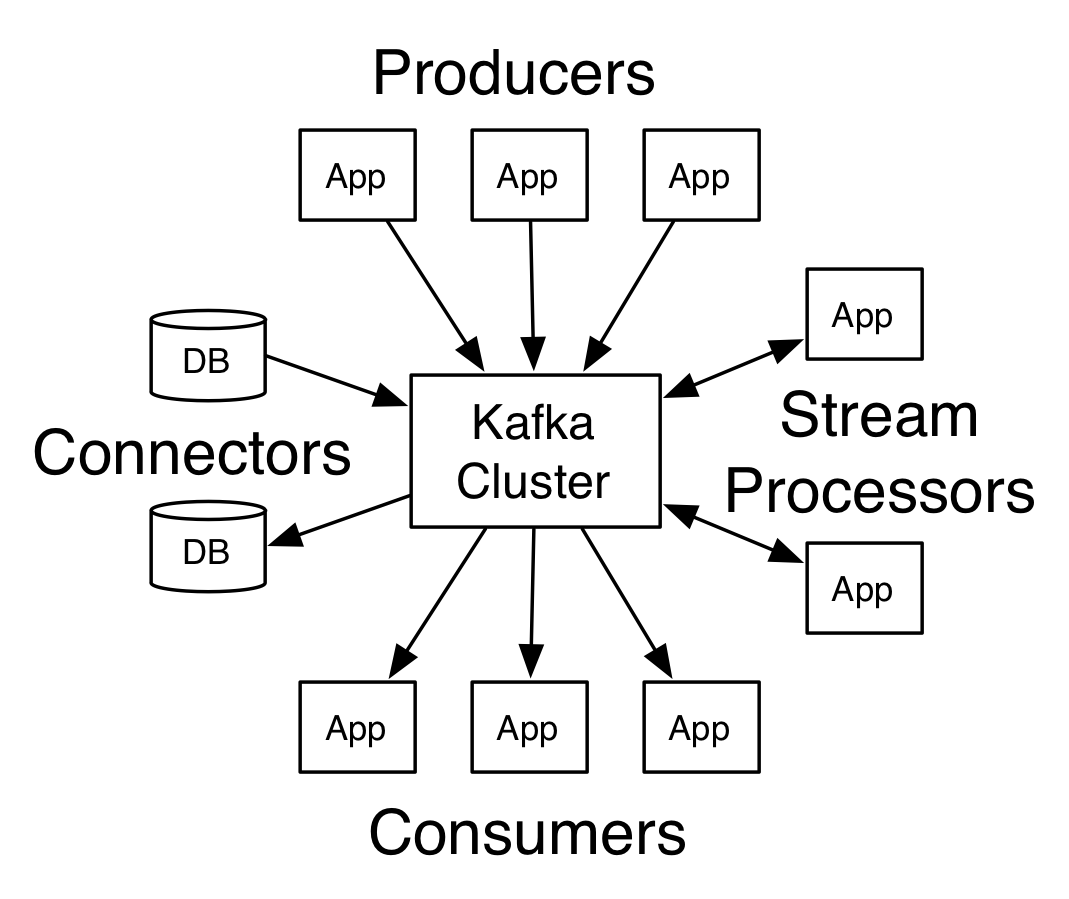
Kafka 作為 client 與 server 兩邊的溝通平台,提供了許多 API 葛不同角色使用。Producer 產生 message 到特定 topic 上,consumer 訂閱特定 topics,kafak 把符合條件的訊息推播給 consumer。
- Producer API: 讓 app publish 一連的訊息
- Consumer API: 讓 app subscribe 許多特定 topic,並處理訊息串流(stream)
- Stream API: 讓 app 作為串流中介處理(stream processor)
- Connect API: 與 producer 與 consumer 可以對外部服務連結
Topics & Logs
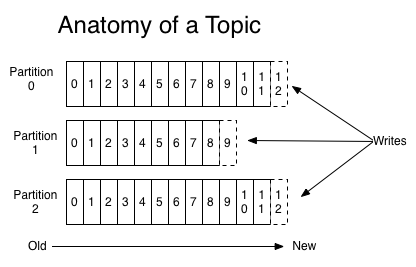
Topic 是 kafka 為訊息串流提供的抽象,topic 是訊息傳送到 kafka 時賦予的類別(category),作為 publish 與 consume 的判斷依據。
Partition
訊息依據 topic 分類存放,並可以依據 replication factor 設定,在 kafka 中存放多個訊息分割(partition)。partition 可以想成是 message queue 的平行化 (parallel),併發處理訊息可以大幅提昇訊息接收與發送的速度,並且多個副本也提高資料的可用性。
由於訊息發送跟接收過程可能因為網路與環境而不穩定,這些相同 topic 的 partition 不一定會完全一樣。但 kafka 確保了以下幾點。
Guarantees
良好配置的 kafka 有以下保證
- 訊息在系統中送出跟被收到的時間不一定,但kafak中,從相同 producer 送出的訊息,送到 topic partition 會維持送出的順序
- Consumer 看見的訊息是與 kafka 中的存放順序一致
- 有 replication factor 為 N 的 topic ,可以容忍(fault-tolerance) N-1 個 kafka-server 壞掉,而不影響資料。
當然,這邊的前提是有良好配置。錯誤的配置可能會導致訊息不穩定,效能低落,甚至遺失。
Producer
Producer 負責把訊息推向一個 topic,並指定訊息應該放在 topic 的哪個 partition。
Consumer
Consumer 會自行標記,形成 consumer group,透過 consumer group 來保障訊息傳遞的次序,容錯,以及擴展的效率。
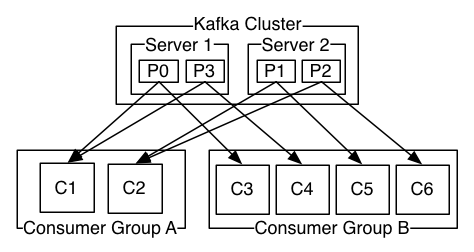
- Consumer 透過 consumer group 共享一個 group.id。
- Consumer group 去所有 partitions 裡拿訊息,所有 partitions 的訊息分配到 consumer group 中的 consumer。
app 在接收訊息時,設置正確的化,在一個 consumer group 中,可以容忍 consumer 失效,仍能確保訊息一指定的次序送達。在需要大流量時,也可調整 consumer 的數量提高負載。
用例
kafka 的使用例子非常的多,使用範圍非常廣泛。
基本上是訊息傳遞的使用例子,kafka 大多能勝任。
小結
這邊只提了 kafka 的基本概念,基本元件,以及 consumer group 機制,為我們底下要談的 configuration 與 topology 鋪路。
Che-Chia Chang
Site Reliability Engineer
My research interests include Site Reliability Engineering, DevOps, Container and Kubernetes.