Deploy Kafka on Kubernetes
Che-Chia Chang
QRCode
About Me
David (Che-Chia) Chang
- Backend / Devops @ MachiX
- Golang Taipei Meetup
- 2020 Ithelp Ironman Challenge
- https://t.me/chechiachang
Outline
- Introduction to Kafka
- Deploy Kafka with Helm
- Kafka Topology
- Ithelp Ironman 30 days Challenge (7th-12nd day)
Introduction
Distributed streaming platform
- Publish & Subscribe: r/w data like messaging system
- Store data in distributed, replicated, fault-tolerant cluster
- Scalable
- Realtime
Concepts
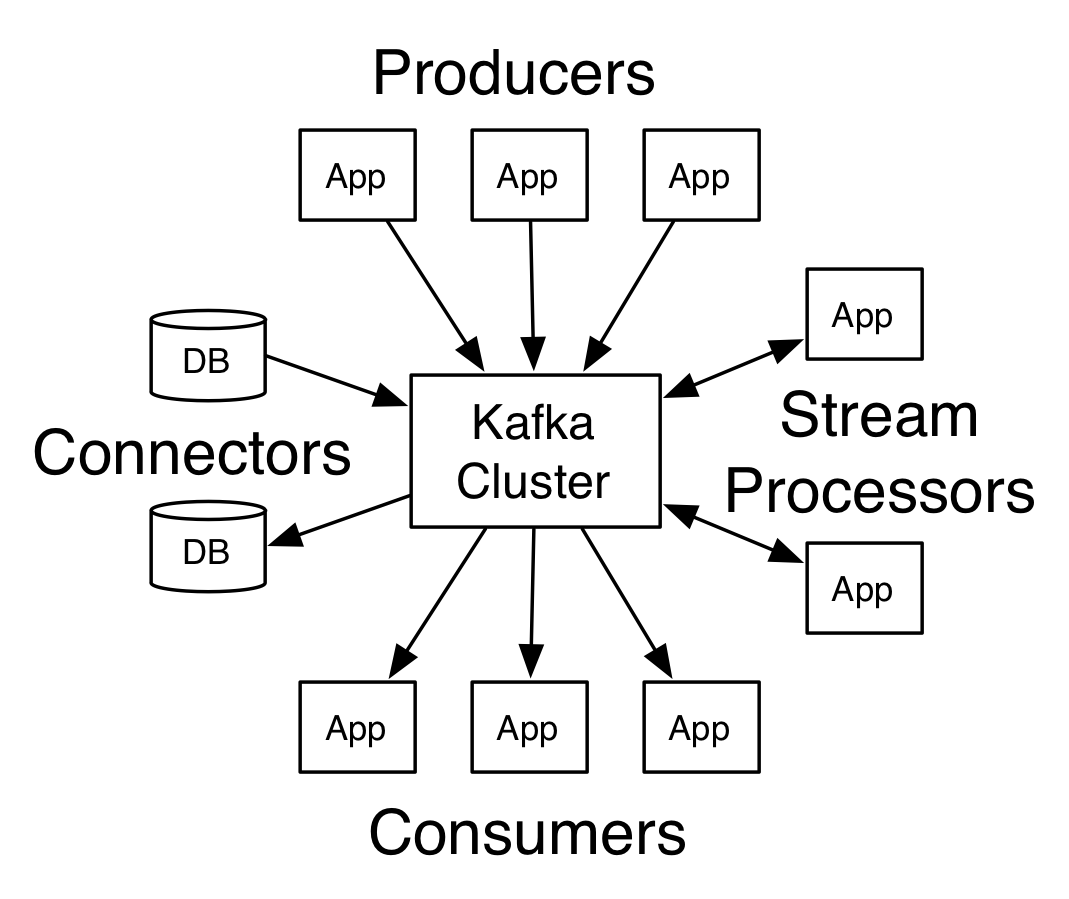
- Kafka run as a cluster
- Kafka cluster stores streams of records in categories called topics
- record = (key, value, timestamp)
Kafka Diagram
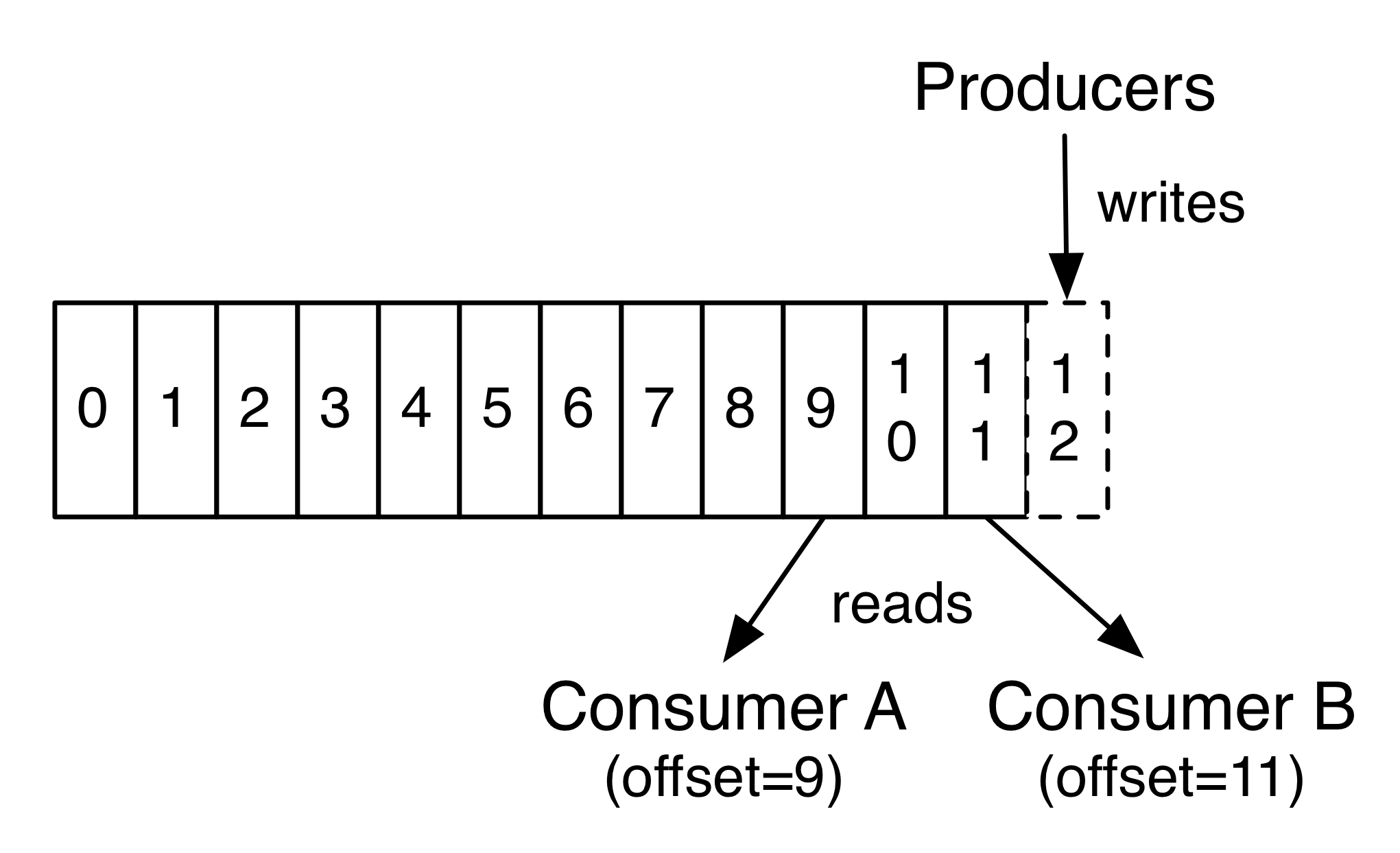
Topic Partitions
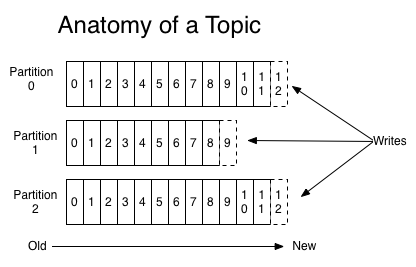
Topic Partitions
- Data categorized by topic
- Data replicated in partitions
- Durability
- consumer able to r/w complete data from at least 1 partition
- in order
Distributed Data Streaming
-
Scalible r/w bandwith
-
Data Durability
-
Consistency
-
Availability
-
Partition Tolerance
Multi Consumer
Consumer Group
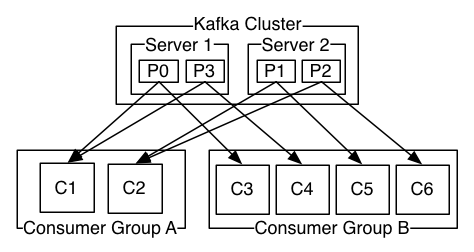
Consumer Group
- Partition deliver record to one consumer within each subscribing consumer group
Deployment
Deployment
https://github.com/chechiachang/kafka-on-kubernetes
cat install.sh
#!/bin/bash
# https://github.com/helm/charts/tree/master/incubator/kafka
HELM_NAME=kafka-1
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
helm upgrade --install ${HELM_NAME} incubator/kafka --version 0.16.2 -f values-staging.yaml
Check values-staging.yaml before deployment
Helm Chart Values
cat values-staging.yaml
# ------------------------------------------------------------------------------
# Kafka:
# ------------------------------------------------------------------------------
## The StatefulSet installs 3 pods by default
replicas: 3
## The kafka image repository
image: "confluentinc/cp-kafka"
## The kafka image tag
imageTag: "5.0.1" # Confluent image for Kafka 2.0.0
## Specify a imagePullPolicy
## ref: http://kubernetes.io/docs/user-guide/images/#pre-pulling-images
imagePullPolicy: "IfNotPresent"
## Configure resource requests and limits
## ref: http://kubernetes.io/docs/user-guide/compute-resources/
resources: {}
# limits:
# cpu: 200m
# memory: 1536Mi
# requests:
# cpu: 100m
# memory: 1024Mi
kafkaHeapOptions: "-Xmx4G -Xms1G"
## The StatefulSet Update Strategy which Kafka will use when changes are applied.
## ref: https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/#update-strategies
updateStrategy:
type: "OnDelete"
## Start and stop pods in Parallel or OrderedReady (one-by-one.) Note - Can not change after first release.
## ref: https://kubernetes.io/docs/tutorials/stateful-application/basic-stateful-set/#pod-management-policy
podManagementPolicy: OrderedReady
## If RBAC is enabled on the cluster, the Kafka init container needs a service account
## with permissisions sufficient to apply pod labels
rbac:
enabled: false
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- kafka
topologyKey: "kubernetes.io/hostname"
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 50
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- zookeeper
topologyKey: "kubernetes.io/hostname"
## Configuration Overrides. Specify any Kafka settings you would like set on the StatefulSet
## here in map format, as defined in the official docs.
## ref: https://kafka.apache.org/documentation/#brokerconfigs
##
configurationOverrides:
"default.replication.factor": 3
"offsets.topic.replication.factor": 1 # Increased from 1 to 2 for higher output
# "offsets.topic.num.partitions": 3
"confluent.support.metrics.enable": false # Disables confluent metric submission
# "auto.leader.rebalance.enable": true
# "auto.create.topics.enable": true
# "controlled.shutdown.enable": true
# "controlled.shutdown.max.retries": 100
"message.max.bytes": "16000000" # Extend global topic max message bytes to 16 Mb
## Persistence configuration. Specify if and how to persist data to a persistent volume.
##
persistence:
enabled: true
## Prometheus Exporters / Metrics
##
prometheus:
## Prometheus JMX Exporter: exposes the majority of Kafkas metrics
jmx:
enabled: true
## Prometheus Kafka Exporter: exposes complimentary metrics to JMX Exporter
kafka:
enabled: true
topics: []
# ------------------------------------------------------------------------------
# Zookeeper:
# ------------------------------------------------------------------------------
zookeeper:
## If true, install the Zookeeper chart alongside Kafka
## ref: https://github.com/kubernetes/charts/tree/master/incubator/zookeeper
enabled: true
Kubernetes Configurations
- replicas
- resource
- pod affinity
- persistence
Kafka Configurations
- zookeeper
- configurationOverrides
"default.replication.factor": 3
"offsets.topic.replication.factor": 1 # Increased from 1 to 2 for higher output
# "offsets.topic.num.partitions": 3
# "auto.leader.rebalance.enable": true
# "auto.create.topics.enable": true
"message.max.bytes": "16000000" # Extend global topic max message bytes to 16 Mb
Monitoring Configurations
-
prometheus exporter
-
monitoring is the key to production
Deploy after Understande Configs
-
All Kafka garantees are based on a correctly configured cluster
-
Incorrect configs will cause cluster unstable and data loss
-
Now we can deploy :)
Pods
$ kubectl get po | grep kafka
NAME READY STATUS RESTARTS AGE
kafka-1-0 1/1 Running 0 224d
kafka-1-1 1/1 Running 0 224d
kafka-1-2 1/1 Running 0 224d
kafka-1-exporter-88786d84b-z954z 1/1 Running 0 224d
kafka-1-zookeeper-0 1/1 Running 0 224d
kafka-1-zookeeper-1 1/1 Running 0 224d
kafka-1-zookeeper-2 1/1 Running 0 224d
Availability
ex. replication factor=3
- 3 partitions, each 1 in a kafka-broker
- 1 master partition 2 slave partitions (readonly)
- data sync from master to slave
Availability
- kafka keep a number of slave in-synced
- too many in-sync -> slow down write confirm
- not enough will -> data loss
On slave failure
- client not affected
- keep enough in-sync slaves
- wait dead slave to back online
On master failure
- slave select new master within in-synced slaves
- new master sync to slaves
- new master serve clients
- wait dead master to back online and become slave
Configs Availability
- Metadata are stored in zookeeper
- topic configs
- partition configs
- consumer offsets
重點
- 要仔細看完 helm chart values 的設定,設錯就幹掉重來
- kafka 的概念與設定,要花時間研究清楚
- resource & JVM heap size
- prometheus is a must
Ithelp Ironman Challenge
-
30 天內容都是 step-by-step
-
內容只是仔細看官方文件
-
challenge -> 自我成長
-
給輸在起跑點的人