RAG workshop 行前通知:基本需求
- 當天帶自己的電腦。當天建議自備手機網路
- 選項1: 用電腦在 docker 運行開發環境
- 選項2: 用電腦遠端連線講師提供的 VM,在遠端VM 中運行 docker 開發環境
- 會使用 docker
- 會使用 python 與 jupyter notebook
選項1: 使用自己的電腦 💻
在 workshop 開始前,在自己的電腦上
- 安裝 docker
- git clone 教材
- 啟動 docker 開發環境,下載 docker images
- 安裝所需的 Python 套件
- 開啟瀏覽器,連線到http://localhost:8888
- 登入token=
workshop1234!
git clone https://github.com/chechiachang/rag-workshop.git
cd rag-workshop
docker compose up -d
docker exec -it notebook pip install pandas openai qdrant_client tqdm tenacity wget tenacity unstructured markdown ragas sacrebleu langchain_qdrant langchain-openai langchain_openai langchain_community tiktoken ipywidgets
選項2: 使用遠端 VM
建議
- 優先使用個人電腦。會盡量提供免費 VM 名額,但依參與人數不保證現場有
- 在家先試跑一遍,把 docker image 跟 pip 套件都下載好,現場要載很久
- 試完後記得關掉 ngrok,以免用完每月的免費額度
- 事先看完內容覺得太簡單可以不用來,但歡迎會後找我聊天XD
投影片與教材與完整程式碼放在網站上
以下是 RAG Workshop 當天內容
可以先看,也可以當天再看

RAG Workshop
關於我
- Che Chia Chang
- SRE @ Maicoin
- Microsoft MVP
- 個人部落格chechia.net 投影片講稿,鐵人賽 (Terraform / Vault 手把手入門 / Etcd Workshop)
- 📝 今天的投影片原始碼與講稿
RAG Workshop 流程
- 10min - 環境設定:確定參與者都有設定好開發環境
- 10min - 為什麼需要 RAG(Retrieval-Augmented Generation)
- 10min - Notebook 2 Embedding 與向量數據庫
- 10min - Notebook 3 Embedding Search
- 10min - Notebook 4 DIY
- 10min - Notebook 5 Evaluation
- 10min - Notebook 6 k8s RAG QA
- 20min - DIY + Q&A
選項1: 使用自己的電腦
- 有在家先試跑一遍,應該可以在本地存取 Notebook http://localhost:8888
- 到 workshop.chechia.net 取得 OpenAI Key
- 可以試著跑 notebook 2-5
- 忘記怎麼啟動,可以回到投影片最開始
notebook token: workshop1234!
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
選項2: 使用遠端 VM
- 至workshop.chechia.net 領取一台 VM 並簽名
- googel sheet 左邊 url,開啟 bastion 連線
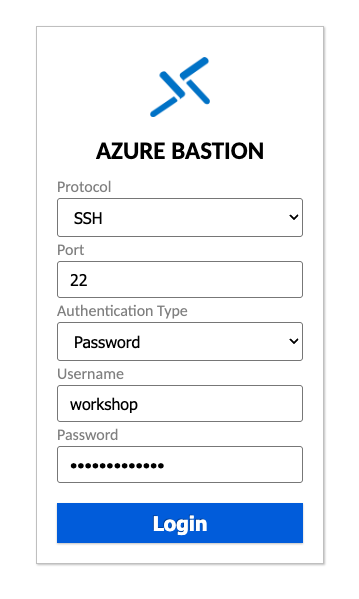
- Protocol: SSH,port 22,authentication type: password
- 帳號密碼在workshop.chechia.net
選項2: 使用 ngrok 連線到 jupyter notebook
- 進入 VM 後,修改下面 ngrok authtoken。指令一行一行貼上(右鍵)到 bastion 中執行
- 透過 https://4d11-52-230-24-207.ngrok-free.app/ 就可以使用 notebook (每個人不一樣)
cd rag-workshop
NGROK_AUTHTOKEN=<改成你的token>
sed -i "s/your-token/$NGROK_AUTHTOKEN/" docker-compose.yaml
docker compose up -d
docker logs ngrok
t=2025-06-02T06:17:41+0000 lvl=info msg="started tunnel" obj=tunnels name=command_line addr=http://notebook:8888 url=https://4d11-52-230-24-207.ngrok-free.app
以上是 Workshop 環境設定
- 後面上課都透過這個網址操作
- 還沒有看到 jupyter notebook 的人,請舉手

RAG Workshop 流程
- 環境設定:確定參與者都有設定好開發環境
- 為什麼需要 RAG(Retrieval-Augmented Generation)
- Embedding 與向量數據庫
- Embedding Search
- DIY
- Evaluation
- 實際應用: 以 k8s official docs 為例
- DIY + Q&A
什麼是 RAG
RAG(Retrieval-Augmented Generation 檢索增強生成)結合檢索系統與生成式模型(如 GPT)的自然語言處理架構,在生成答案時引用外部知識,使模型回答更準確且具事實根據
- Retrieval(檢索): 從一個外部知識庫(如文件、向量資料庫等)中找到與問題相關的資訊。通常會用語意向量(embeddings)做相似度搜尋。
- Generation(生成): 把檢索到的內容與使用者問題一起丟給 LLM(如 GPT、Claude 等)去生成答案。生成的內容會更具事實根據,並能引用具體資料。
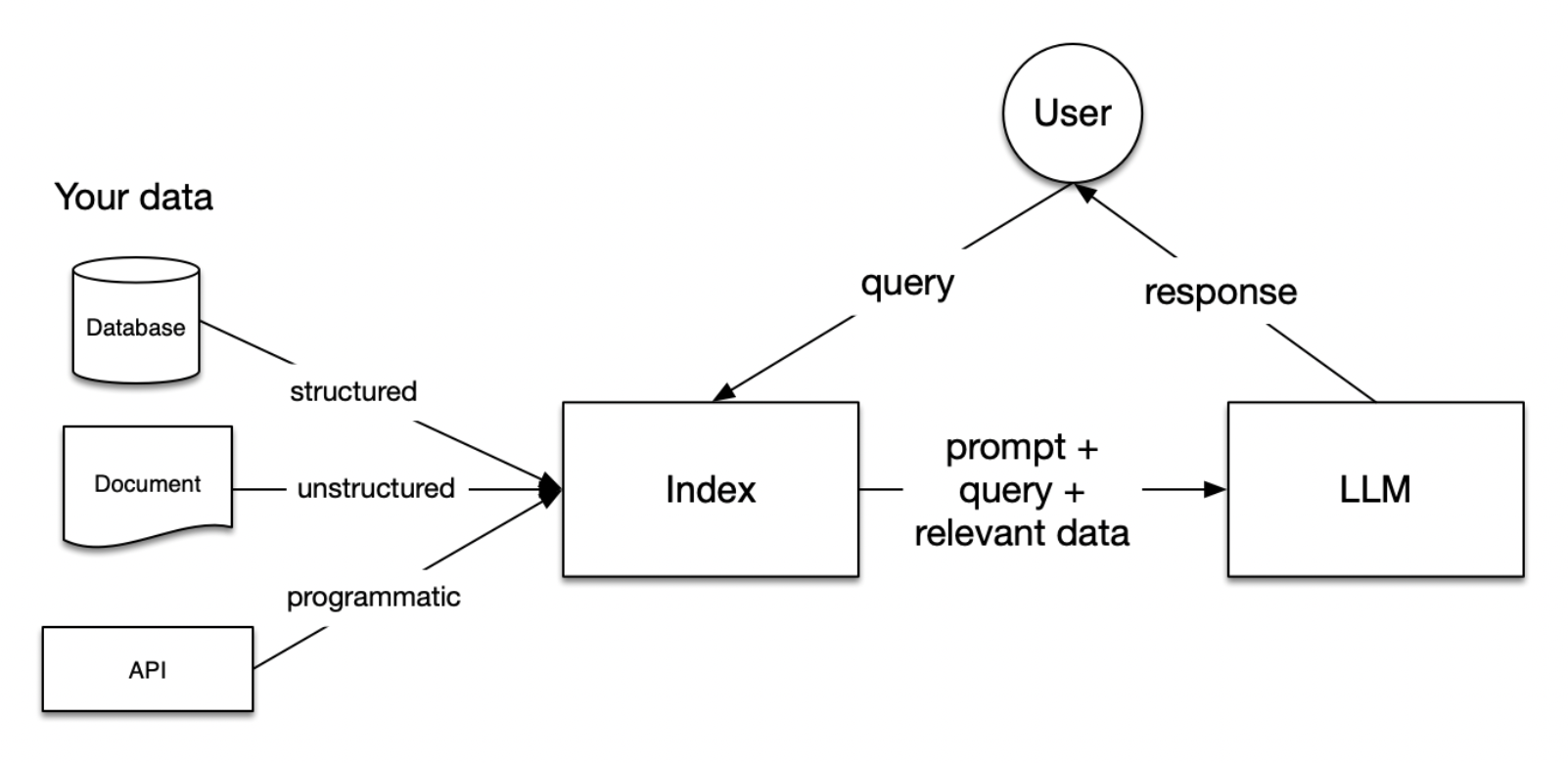
https://cookbook.openai.com/images/llamaindex_rag_overview.png
知識獲取效率在 DevOps 的難題
在快速變動、資訊分散的環境中,難以即時取得需要的知識。「有但找不到、看不懂、用不起來」
- 知識分散在多個系統、格式與工具中
- 知識多為「靜態文件」,難以互動問答,舉例,或是換句話說
- 隱性知識未被系統化儲存(例如:口頭傳承、slack 討論、會議紀錄等)
- 查詢流程與開發流程脫節
情境:新人工程師要如何到 k8s doc 查到想要的內容?
- 有問題去 google / stack overflow
- 需要搜尋引擎(k8s doc 有提供,但內部文件系統不一定有)
- 需要關鍵字(新人怎麼知道要查 Dynamic Persistent Volume Resizing)
- 協助理解(舉例,換句話說)
- 跨語言門檻

情境:Senior 工程師要如何分享知識?
- 『我有寫一篇文件在某個地方,你找一下』
- 『我忘記去年為什麼這樣做了』
- 『我去 Slack 上找一下』
- 『你要不要先去問 ChatGPT?』

RAG 讓 DevOps 更智慧的即時反應
- 提升知識獲取效率: 內部文檔知識AI助手
- 知識留存與新人 Onboarding
- 加速故障排查: 根據錯誤訊息自動從 Runbook 中檢索處理方式
- 優化流程自動化與提升決策品質: 通訊軟體對話 bot,自動生成建議
DevOps AI Copilot 不應該像圖書館守門員等人來借書, 而應該像導航系統,在你開車時主動告訴你:前方有彎道。
RAG + Context-Aware Knowledge Copilot
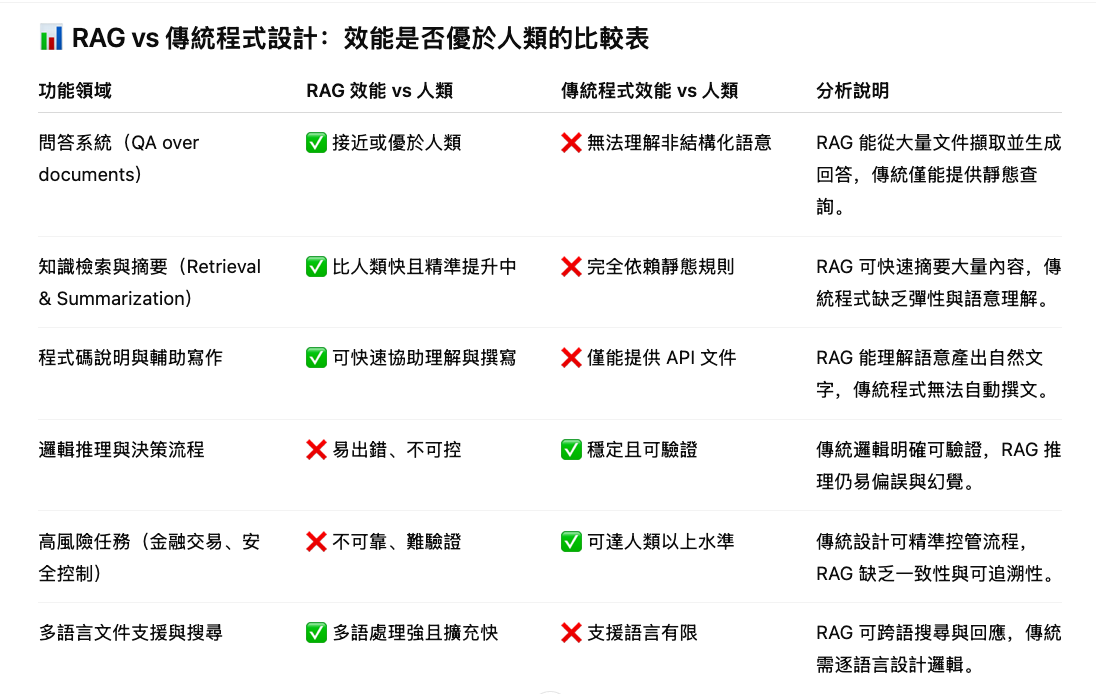
RAG vs 其他工具
- 需要工具提升知識獲取效率,如何選擇 RAG 或是其他 non-LLM 工具?例如 search engine / fulltext search engine / search algorithm
- 特定任務的效能是否優於人類
- 哪裡適合用 RAG,哪裡適合用 non-LLM 工具
有了大語言模型後
- 去 google -> 先問 chatgpt,初步問答理解問題,找到關鍵字
- 需要搜尋引擎 -> chatgpt 整合,直接上網搜尋
- 需要關鍵字 -> chatgpt 幫你找到關鍵字
- 協助理解 -> chatgpt 舉例,換句話說
- 跨語言門檻 -> chatgpt 翻譯
- chatgpt 會用通順的語言,快速(數秒內)上網搜尋,回答問題
- 過程中不厭其煩地問答,換句話說
- 回答的格式高度客製化
LLM 不具備專業知識。缺乏內容根據時,容易產生幻覺(hallucination)

RAG Workshop 流程
- 環境設定:確定參與者都有設定好開發環境
- 為什麼需要 RAG(Retrieval-Augmented Generation)
- RAG 在「文件檢索與提示」上優於人類
- LLM 補強工程師的語言能力
- Embedding 與向量數據庫
- Embedding Search
- DIY
- Evaluation
- k8s RAG QA.ipynb
RAG Workshop 流程
- 確定參與者都有跑一套RAG起來
- Evaluation
- k8s RAG QA.ipynb
如何評估 RAG 系統的品質?
- 人人都會下 prompt,但是誰的 prompt 更好?或是沒差別?
- 如何選擇 vector store 的 chunking 策略?
- 哪個 retriever 更好?
- 要如何持續改善 RAG 系統?下個迭代的改善方向是什麼?
- 是否符合 production criteria?
評估:確保回答品質可靠性與可控性
- 保證正確性:檢索出的資訊是正確的,生成的答案忠實於原始 context
- 降低幻覺風險:即使有資料,LLM 仍可能亂編
- 測量系統品質
- 改善依據:幫助驗證Chunking 策略,Prompt 設計,Retriever 模型調整
- 自動化監控:品質追蹤、問題定位,建立類似 APM 的 QA 指標
- 對 Stakeholder 展示成效:可視化與量化指標,有助溝通與資源投入
RAG 應用: 以 k8s official docs 為例
總結
- 為什麼需要 RAG
- Embedding 與向量數據庫
- Embedding Search
- DIY
- Evaluation
- k8s RAG QA
由衷地感謝為 workshop 提供協助的夥伴!
MaiCoin: We are Hiring!!
DIY + Q&A + 建議
- 下次會改用 Colab